
Writing a Python script to fetch 100 pages is a simple task. It runs locally, finishes in seconds, and stores data in a simple CSV.
Moving that same logic to scraping millions of pages creates a completely different reality.
Speed, cost, and reliability immediately become major obstacles. A script that works perfectly for small batches will likely crash, get blocked, or run out of memory when targeted at high volume web scraping.
Scaling is not just about running a loop longer. It requires a fundamental shift in how you design your data collection systems.
We’ll explain the exact architecture needed for enterprise web scraping. We will look at why local threads fail, how to manage bandwidth, and why using Decodo for unlimited concurrency proxies solves the biggest bottleneck in the industry.
The Concurrency Myth: Why Local Threads Fail in Scalable Web Scraping

A common misconception in web scraping infrastructure involves threading. Developers often believe that simply adding more threads to a Python script will solve speed issues. While multithreading helps, it has hard limits.
If your internet connection or your proxy provider bottlenecks you, 500 threads will perform just as poorly as 50. This is where the concept of unlimited concurrency proxies becomes vital.
Your local machine might open 100 connections, but if your proxy provider throttles concurrent sessions, 90 of those requests will hang or timeout. True scaling requires a partner that doesn’t artificially limit your throughput.
Decodo addresses this specific pain point. Unlike standard providers that cap your simultaneous connections, Decodo offers highly scalable infrastructure that supports unlimited concurrent sessions.
This allows you to push your hardware to its absolute limit, constrained only by your own server’s CPU and bandwidth, not by your proxy service.
Architecting for Scale: From Local Scripts to Enterprise Pipelines
Learn the key architectural shifts required to scale web scraping from hundreds to millions of pages efficiently and reliably.
Step 1: Async is King (Abandoning Synchronous Code)

Standard Python requests are synchronous. Your code sends a request and waits. The program does absolutely nothing until the server responds.
$$Time_{total} = \sum_{i=1}^{n} (Time_{connect} + Time_{download})$$If a page takes 2 seconds to load, fetching 1,000 pages takes over 30 minutes sequentially.
To achieve scraping at scale, you must move to asynchronous web scraping python.
Using libraries like aiohttp and asyncio, your scraper sends a request and immediately moves to the next task without waiting for a response. The program handles thousands of open connections simultaneously.
This switch typically results in performance gains of 10-20x over synchronous scraping. The CPU is no longer idle; it manages traffic efficiently.
Building High-Speed Event Loop Scrapers in Python
The core of python asyncio scraping relies on an event loop. The loop manages tasks, switching focus whenever a task waits for external data.
This architecture is non-negotiable for enterprise projects. Without it, you cannot physically push enough requests through the network to hit daily targets of 500k+ pages.
Step 2: Scaling Beyond One Server with Distributed Scraping
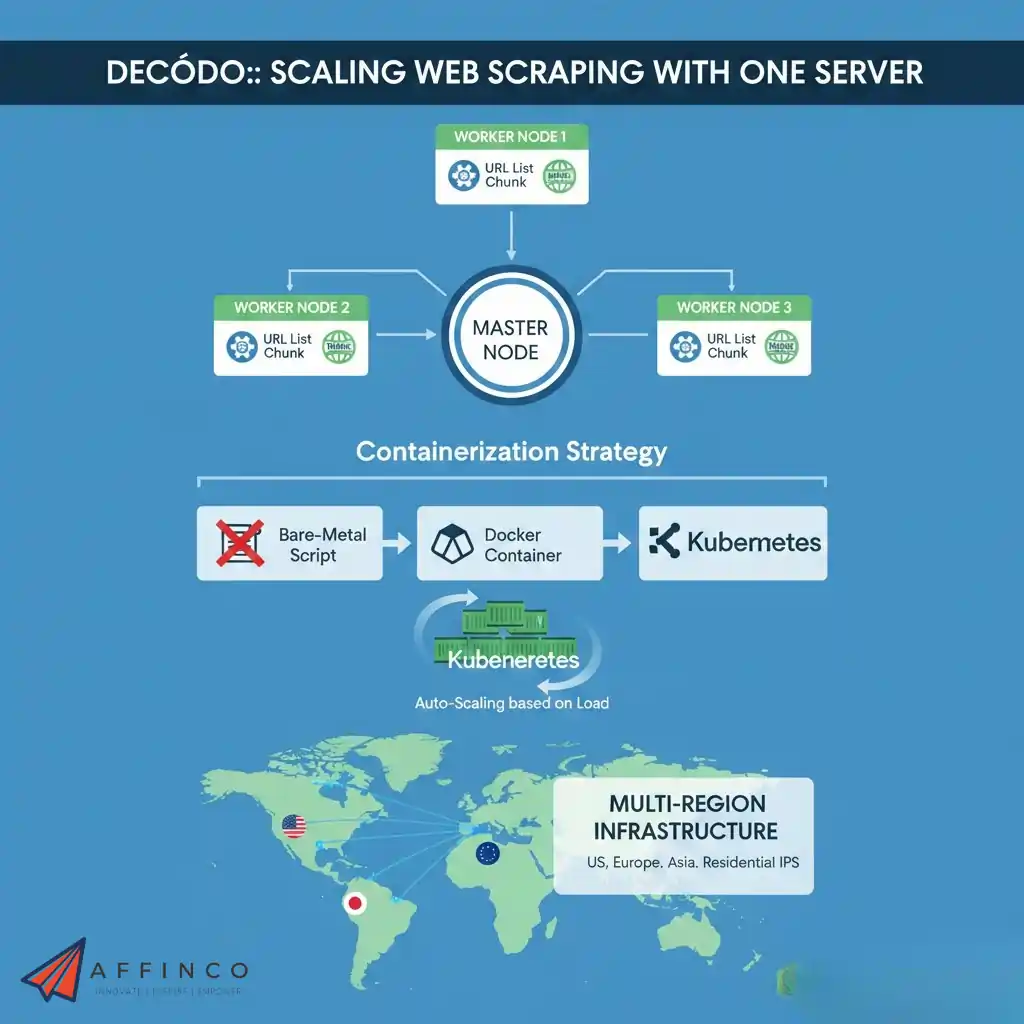
Even with async code, a single server has limits.
Network cards (NICs) have bandwidth caps. CPUs can only manage so many open file descriptors. Once you aim for millions of daily requests, you must separate the workload.
You need distributed web crawling.
This involves breaking your target list into chunks. A central “master” node distributes these URLs to multiple “worker” nodes.
Containerization Strategy
Do not run bare-metal scripts. Wrap your scrapers in Docker containers.
Containers allow you to spin up identical environments instantly. If you need to double your speed, you simply launch more containers.
Orchestration tools like Kubernetes can manage this automatically, scaling your web scraping infrastructure up or down based on current load.
Decodo supports this effortlessly. Since Decodo provides a multi-region infrastructure, your distributed workers can run from servers in the US, Europe, or Asia, and Decodo routes the traffic through the appropriate residential IPs instantly.
Step 3: From Raw HTML to Database: Stream Data Smartly

A common mistake is storing data in memory.
Beginners often append scraped data to a Python list, intending to save it to a CSV at the end.
If you scrape 10,000 pages, this works. If you scrape 1 million pages, your server runs out of RAM and crashes before saving a single byte. Enterprise web scraping requires streaming pipelines.
Direct-to-Database Architecture
As soon as data arrives, validate it and push it to a database.
This ensures that if a worker node crashes, you only lose the single page currently being processed, not the entire day’s work.
Decodo Infrastructure: Powering Enterprise-Scale Web Scraping

Architecture is useless without fuel. In scraping, the fuel is your proxy network.
Many providers claim “high performance” but fail under the load of scraping millions of pages. They suffer from high latency, frequent timeouts, or IP bans.
Decodo focuses specifically on high volume web scraping needs.
Why Decodo Fits Enterprise Needs:
Decodo delivers unmatched scalability, reliability, and cost efficiency for mission-critical scraping operations, ensuring your business never misses a beat.
Handling Failures: The Dead Letter Queue
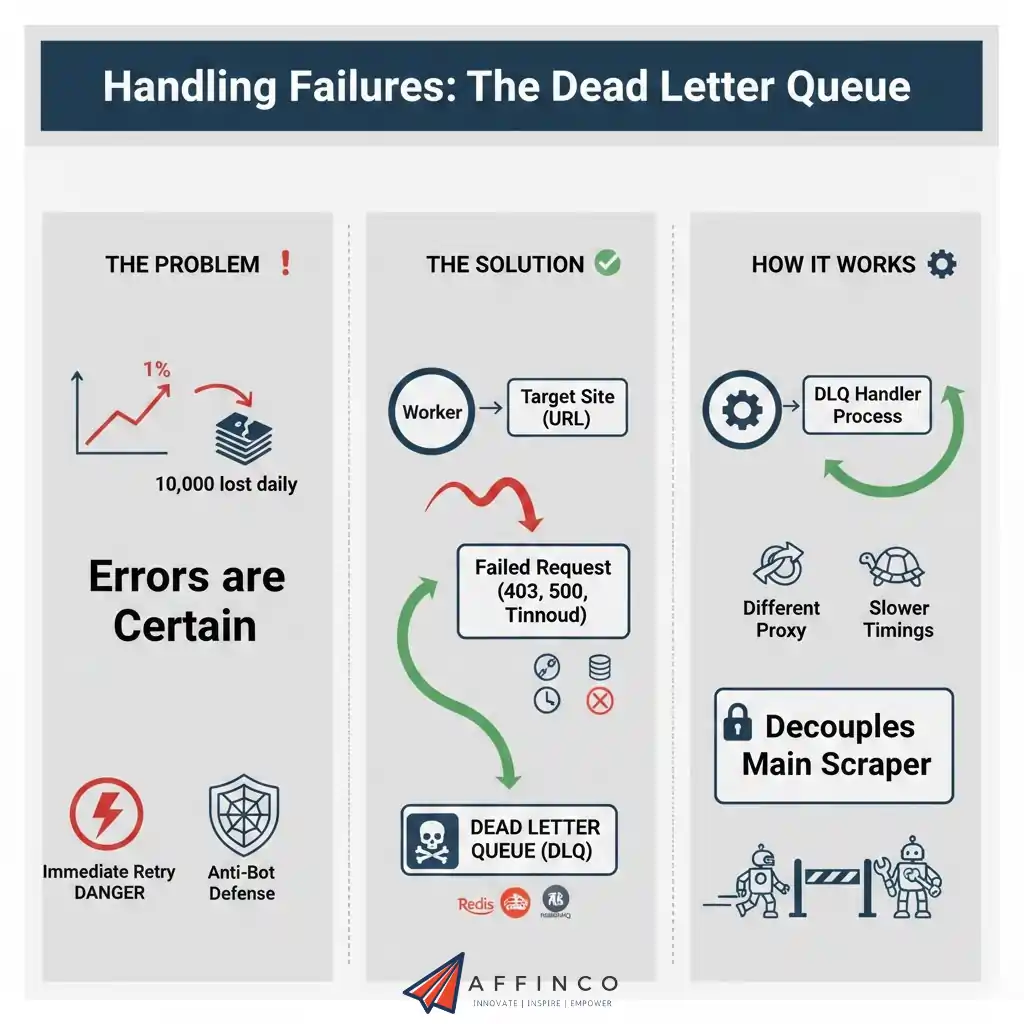
At scale, errors are statistical certainties.
If your failure rate is 1%, and you scrape 1,000,000 pages, you lose 10,000 records daily.
Ignoring errors is not an option. However, retrying immediately is also dangerous. Immediate retries can trigger anti-bot defenses if the target site is temporarily blocking you.
Implementing a DLQ
Use a “Dead Letter Queue” (DLQ).
This decouples your main high-speed scraper from the messy work of fixing errors.
Turning Small Scripts into Enterprise Data Machines
Scaling from a simple script to an enterprise architecture requires a shift in thinking. You must move away from linear loops and text files.
Adopt asynchronous web scraping python techniques. Build a distributed system that can survive failure. Stream your data to robust databases.
Most importantly, choose infrastructure that supports growth.
Data is the lifeblood of modern business. Do not let your IP provider be the clot that stops the flow. Decodo offers the highly scalable infrastructure necessary to handle millions of requests.
With the right architecture and Decodo handling the connections, you can stop worrying about blocks and start focusing on the insights your data provides.

Ali
Ali is a digital marketing expert with 7+ years of experience in SEO-optimized blogging. Skilled in reviewing SaaS tools, social media marketing, and email campaigns, we craft content that ranks well and engages audiences. Known for providing genuine information, Ali is a reliable source for businesses seeking to boost their online presence effectively.





