
The 2026 World Cup is the most demanded ticket in football history. FIFA confirmed it received more than 500 million ticket requests in a single application window, for a 48 team tournament spread across the United States, Mexico, and Canada.
When inventory drops, it disappears in minutes, and hitting refresh by hand is a losing game. This guide shows marketers and proxy users how to monitor FIFA 2026 ticket availability programmatically, why rotating proxies are non negotiable for the job, and how to assemble a clean, reliable scraping stack.
One ground rule before we start, and we will repeat it because it matters: scrape only public availability data, respect every platform's terms of service, and never automate the actual checkout or use bots to jump the queue. FIFA stresses that its official platform and resale marketplace are the only authorized purchase channels, and the 2026 cycle is already crawling with fraud and scam operations. You are building a monitor, not a buying bot.
Who This Guide Is For
If you run affiliate or media properties around travel, sports, or proxies, FIFA 2026 is a once in a generation seasonal traffic spike.
A live availability tracker is the kind of tool that earns links, builds authority, and converts proxy and scraping signups. If you are new to the topic, start with our primer on rotating proxies and the broader explainer on web scraping proxies, then come back here for the FIFA specific build.
Why You Need Rotating Proxies Here
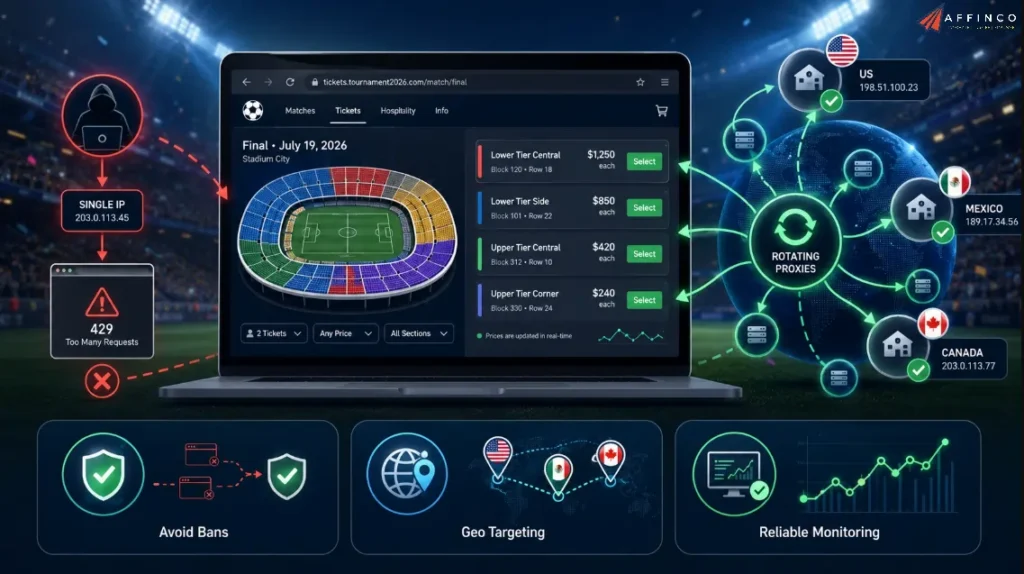
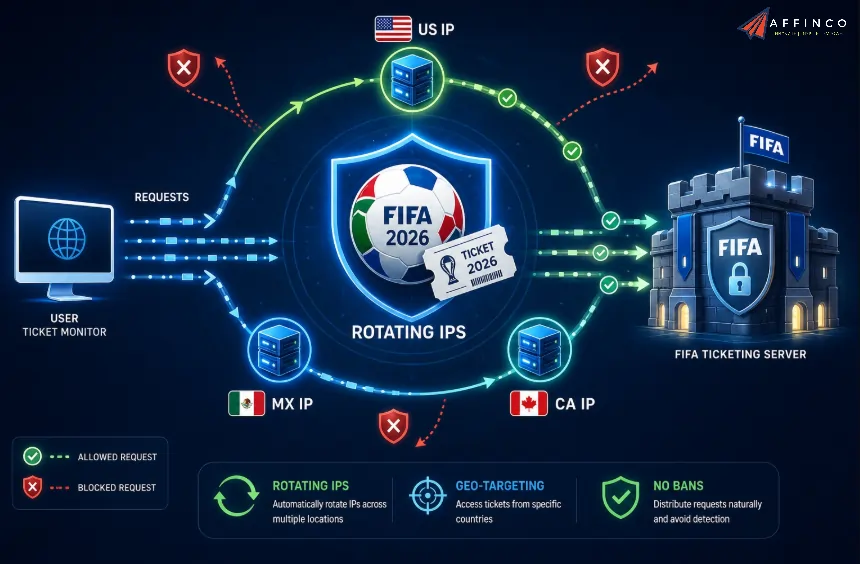
FIFA's ticketing and resale pages are high traffic, heavily protected, and geo sensitive. Fire a script at them from one IP address and you get rate limited or blocked within a handful of requests. Rotating proxies fix this by cycling requests through a large pool of residential or datacenter IPs, so each call looks like an ordinary visitor.
Three reasons rotation matters specifically for FIFA 2026:
Used responsibly, rotation is about reliability and politeness. You space out a normal monitoring cadence, you do not flood a server. Our guide on how to avoid IP bans while scraping covers the request hygiene that keeps a long running monitor healthy.
Quick Comparison of the Proxy Stack
For this job you want a residential or rotating pool with strong North American coverage. Three providers span budget to premium, and you can mix them depending on scale.
| Provider | Best for | Network type | Why it fits FIFA monitoring |
|---|---|---|---|
| Webshare | Budget and beginners | Datacenter plus rotating residential | Cheapest entry point, ranked among the top rotating services in 2026, generous free tier for testing. |
| Decodo | Balanced mid scale | Large residential pool | Strong geo targeting and high success rates on protected sites, simple rotation endpoints |
| NodeMaven | Premium, sticky quality | Residential with high IP cleanliness | Filters low quality IPs so you see fewer blocks on aggressively defended ticket pages |
A practical pattern: prototype on Webshare's free tier, then graduate to Decodo or NodeMaven once you scale the number of matches you track. If you want a deeper teardown of Decodo's tooling, see our Decodo Web Scraper walkthrough, and for picking nodes by host country, our Mexico proxy providers roundup is directly relevant to a tri nation tournament.
Where the Availability Data Actually Lives
Before writing any code, map your targets. There are three layers of FIFA 2026 ticket data worth monitoring:
Tip: open the page, then use your browser's Network tab to see whether availability loads from a clean JSON API endpoint. Many ticketing seat maps fetch from a backend API, and reading that endpoint is far more efficient than parsing rendered HTML. A community Chrome tool for the 2026 resale marketplace works exactly this way, pulling every seat and price from the page's own data layer.
The Modern Approach: Let Firecrawl Handle the Hard Part
Here is the honest truth about scraping a JavaScript heavy ticketing site by hand: you will spend most of your time fighting rendering, proxies, retries, and parsing instead of analyzing tickets. This is where Firecrawl changes the math.
It is a web data API that takes a URL and returns clean, structured, LLM ready data, handling JavaScript rendering, smart waiting, and proxy management for you.
Firecrawl renders JavaScript automatically, so single page apps and dynamically loaded seat maps return full content with no extra config, and its hosted engine manages proxies and rendering internally so you avoid the proxy plumbing entirely.
You can also pass a JSON schema and get structured data back in the exact shape you want, with no manual parsing.
Firecrawl scrape, the simplest version
Pull a single page and get clean Markdown back. This is your fastest path to a working prototype.
python
from firecrawl import FirecrawlApp
app = FirecrawlApp(api_key="fc-YOUR_API_KEY")
result = app.scrape_url(
"https://www.fifa.com/en/tournaments/mens/worldcup/canadamexicousa2026/tickets",
params={"formats": ["markdown", "html"]}
)
print(result["markdown"])Extract structured availability with a schema
Instead of regexing HTML, describe the data and let Firecrawl return JSON. This is the part that makes your tracker maintainable.
python
schema = {
"type": "object",
"properties": {
"matches": {
"type": "array",
"items": {
"type": "object",
"properties": {
"match": {"type": "string"},
"venue": {"type": "string"},
"date": {"type": "string"},
"category": {"type": "string"},
"price": {"type": "string"},
"available": {"type": "boolean"}
}
}
}
}
}
result = app.scrape_url(
"https://www.fifa.com/...tickets",
params={"formats": ["json"], "jsonOptions": {"schema": schema}}
)
print(result["json"]["matches"])The schema approach survives layout changes far better than CSS selectors, which is exactly what you want for a page FIFA will redesign repeatedly through the tournament.
DIY Path: Rotating Proxies With Python
If you would rather run your own requests, here is the lean version using a rotating endpoint. Most providers, including Decodo, Webshare, and NodeMaven, give you one gateway host that rotates the exit IP on every request.
python
import requests, time, random
PROXY = "http://USER:PASS@gateway.decodo.com:7000"
proxies = {"http": PROXY, "https": PROXY}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36",
"Accept-Language": "en-US,en;q=0.9",
}
def check(url):
r = requests.get(url, headers=headers, proxies=proxies, timeout=20)
r.raise_for_status()
return r.json()
urls = ["https://api.example-ticketing.com/availability?match=USA-MEX"]
for u in urls:
try:
data = check(u)
print(data)
except Exception as e:
print("retry later:", e)
time.sleep(random.uniform(8, 20)) # polite, randomized cadenceThree habits keep this stable:
For tougher targets where even good residential IPs hit walls, pairing rotation with an antidetect browser helps. See our guides on antidetect browsers and the residential proxies used by sneaker bots, since the high demand drop mechanics are nearly identical to a World Cup ticket release.
Building a Real Availability Alert System
A monitor is only useful if it tells you the moment something changes. The simplest reliable loop looks like this:
- Pull current availability for each match you care about, through Firecrawl or your own proxied requests.
- Compare against the last snapshot you stored.
- On any change from sold out to available, fire an alert to Telegram, email, or a webhook.
- Log every check so you can chart demand patterns later.
Store snapshots in a small database or even a flat JSON file keyed by match and category. The diff is what matters, not the raw page. For delivery, a Telegram bot is the fastest channel for instant pings, and our Telegram proxies guide covers keeping that bot connection clean if you run it at scale.
If you would rather not maintain servers at all, a managed scraping platform plus a scheduler does the heavy lifting, and you focus on the alert logic and the content around it.
Staying Legal and Ethical
This is the section most scraping tutorials skip, and it is the one that protects your brand and your domain. Keep these guardrails in place:
Build it this way and your tracker becomes a genuine E E A T asset rather than a liability.
Recommended Stack at a Glance
| Layer | Tool | Role |
|---|---|---|
| Rendering and extraction | Firecrawl | Handles JavaScript, proxies, and structured output in one API |
| Budget rotating proxy | Webshare | Cheap testing and light monitoring with a free tier |
| Scaling proxy | Decodo | Reliable residential rotation with strong geo control |
| Premium proxy | NodeMaven | Cleanest IPs for the most defended pages |
| Alerts | Telegram bot or webhook | Instant notification on availability change |
The Bottom Line
Scraping FIFA 2026 ticket availability comes down to three decisions: where the data lives, how you rotate IPs to read it reliably, and how you alert the moment inventory moves. Rotating proxies from Webshare, Decodo, or NodeMaven keep you unblocked across all three host countries, while Firecrawl removes the rendering and parsing grind so you ship a working tracker in an afternoon.
Stay on the public, ethical side of the line, send buyers to official channels, and you have a seasonal tool that earns traffic and trust during the biggest football event ever staged.
Ready to build it? Spin up your free Firecrawl key, point it at the FIFA tickets page, and have your first structured availability feed running today.

Ali
Ali is a digital marketing expert with 7+ years of experience in SEO-optimized blogging. Skilled in reviewing SaaS tools, social media marketing, and email campaigns, we craft content that ranks well and engages audiences. Known for providing genuine information, Ali is a reliable source for businesses seeking to boost their online presence effectively.





